12月15日,距离Intel发布第一代锐炫A系列桌面级显卡,已经过去2年多的时间。而现在,令人期待的第二代锐炫B系列显卡终于和大家见面了,今天为大家带来的则是ONIX LUMI B580 OC显卡的首测。
这是一款2000元左右价位的显卡,但却有着超乎于价位的做工用料设计,这一点从它质感十足的外观上就能看出,而且首发即采用对于良品率要求更高的白色外观,充分展现了ONIX(傲世)品牌的自信,也满足了用户装机多样化的需求,符合时下DIY高颜值白色主机的潮流。
作为Intel独显新晋品牌,ONIX(傲世)想必大家还比较陌生。ONIX距今已成立13年,共有420余人的研发团队。而作为Intel一直以来的合作伙伴,虽然第一次推出自己的独立显卡,但曾获Intel钛金级合作伙伴、亚洲区最佳合伙人等殊荣。
对于DIY配件来说,尤其是显卡领域能有新鲜血液还是相当令人期待的。一方面,Intel仅依靠下游少数的合作品牌,难以将声量快速铺开;另一方面,对于玩家来说,这也是非常积极的信号,对于Intel的信任又更多了几分。

说回显卡本身,简单概括一下这次Intel首发的B580,就是够稳、够强、够全面。从实测结果来看,绝对可以用惊艳来形容!
虽然从性能来说,它仍是处于主流层面的2000元价位段显卡,但在产品本身的兼容适配,相比A系列显卡首发时,有着天翻地覆的变化。
且12GB大显存以及光追性能的大幅提升,搭配本就出色的多媒体性能,让B580这张显卡称为“全能”也并不过分。
下面我们就先来看看新的B系列显卡架构。
Xe 2架构解析

首先我们需要明确一个定位:锐炫A系列是为1080p、2K游戏而生,而锐炫B系列就是为2K甚至4K环境下的高画质游戏体验而设计,这意味着它的性能必须要经得起考验。
先来看看锐炫B580的规格:它拥有5个渲染切片,集成20个第二代Xe核心,配备20个光追单元,160个XMX AI引擎,默认频率2670MHz,配备12GB显存,192bit位宽,带宽速率456GB/s,INT8峰值算力233TOPS,总TBP为190W。支持PCIe4.0 x8,支持AV1等主流编解码,配备3个DP2.1和1个HDMI2.1视频端口。三个DP口中,最中间的可以输出完美的4K@120Hz画面。
架构层面,英特尔对直接影响性能的Xe核心和光追单元进行了增强。
前者体现在新的矢量引擎中,除了继续支持原生SIMD 16计算,还增加了对SIMD 32的支持。虽然不是原生支持,但已经能够执行SMID 32指令。
而后者的变化相对更大:traversal pipeline的数量提升到3个;box intersections增加到18个;triangle intersections增加到2个,并且扩展了BVH(层次包围体结构)缓存,从而极大地提高了光追单元的速度和效率。
接下来的这张图是锐炫B系列GPU的SoC架构设计示意图,代号BMG-G21。从这张图上可以看到包括Render Slice(渲染切片)、Media Engine(媒体引擎)、Memory Fabric(显存总线)、Display Engine(显示引擎)、Copy Engine(复制引擎)、Memory Controller(显存控制器)等在内的各个计算单元、I/O单元的详细构成。
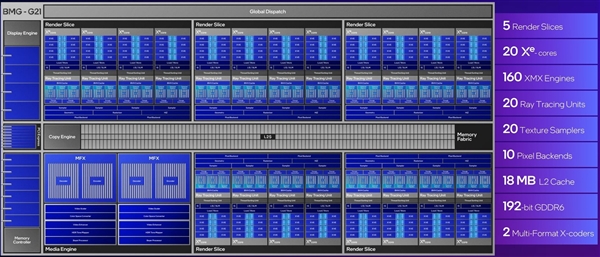
这里我们主要来看看Render Slice(渲染切片),因为它是锐炫GPU最为核心的部分,第二代锐炫GPU的各项提升也都来自这里。
可以看到,一个渲染切片里包含4个Xe核心以及4个光追单元。锐炫B580拥有5个渲染切片,因此就包含了20个Xe核心以及20个光追单元。每个Xe核心拥有8个XMX AI矩阵引擎,那么锐炫B580自然就是有160个XMX AI矩阵引擎。
第二代Xe核心中的XVE(矢量引擎)取代了Xe-LP架构时代的EU(执行单元)。这里需要做一些解释:XVE和以往的EU(执行单元)都是Xe架构里最小的线程级单元,二者概念上相同,只是在具体实现上有一定差别,不过这一点无需深究。前面所说的Xe核心增强,实际上就是XVE、XMX等部分的增强。
此外,渲染切片还包含了10个Pixel Backends(像素后端)和20个Texture Samplers(纹理采样器)。第二代Xe核心还新增了256KB的共享L1/SLM(共享本地内存)。
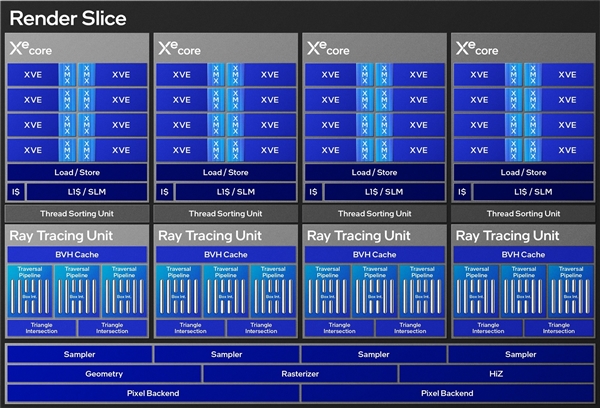
很多朋友可能会想要了解英特尔的这些单位与N卡对应的话该如何换算。其实以B580的5个渲染切片配置来说,对应的就是80个ROPs和160个TMUs,因为纹理采样器转换为TMUs的比为8:1,所以8 x 20就等于160个TMUs;同理,像素后端对应N卡的ROPs,8×10也就是80个ROPs。这部分大家有兴趣的话了解一下即可,对普通用户来说不重要。
第二代锐炫GPU渲染切片中的Xe核心、光追单元升级,显现到“前台”的就是在效率上的显著提升。如果与第一代英特尔锐炫GPU,即锐炫A系列相比的话,B系列现在每个Xe核心的性能提高了70%,每瓦性能提高50%。