11月16日,这年头,安卓厂商没个大模型,都不敢开手机发布会了。
前脚OPPO刚用大模型升级了语音助手,后脚vivo就官宣自研手机AI大模型;
小米发布会则直接将大模型当场塞进手机系统……其竞争激烈程度,不亚于抢芯片首发。

到底是怎么回事?
究其原因,还是智能终端已经成为了各类AIGC应用的落地“新滩头”。
先是图像生成大模型接二连三地被塞进手机,从十亿参数的Stable Diffusion,在手机上快速生成一只金毛小狗:

△图源油管Android Authority
到手机上运行十五亿参数的ControlNet,快速生成一张限定图像结构的AI风景照:

随后,文本生成大模型们也争先恐后地推出了手机新应用——
国内有文心一言、智谱清言APP,国外则有OpenAI的移动版ChatGPT,Llama 2手机版也在加急准备中。
现在,这一波智能终端大模型热潮之中,最底层的软硬件技术齿轮开始转动。
从高通到苹果,最新的芯片厂商发布会,无一不在强调软硬件对机器学习和大模型的支持——
苹果M3能运行“数十亿参数”机器学习模型,高通的骁龙X Elite和骁龙8 Gen 3更是已经分别实现将130亿和100亿参数大模型装进电脑和手机。
并且这不仅仅是已支持或跑通的数字参数,而是实实在在到了可落地应用的程度。

△高通现场演示和手机中的百亿大模型对话
从十亿到百亿,更大参数的移动端AI模型暗示了更好的体验,但也意味着一场更艰巨的挑战——
或许可以将这样机遇与挑战并存的大模型时代,称之为「模力时代」。
「模力时代」下,芯片厂商究竟要如何冲破大模型移植智能终端面临的算力、体积和功耗等限制?
进一步地,大模型的出现又给底层芯片设计带来了哪些改变?
是时候掰开揉碎,好好分析一番了。
「模力时代」,硬件围绕AI而生
从大模型风暴刮起之初,算力就成为了科技圈的焦点话题。
就在最近,OpenAI还因为DevDay后“远超预期”的大模型调用流量,出现了全线产品宕机的史上最大事故。
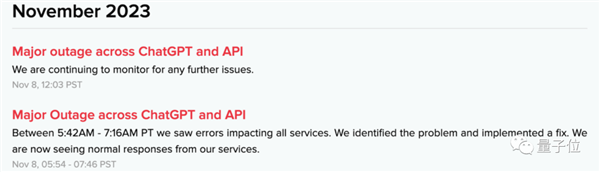
相比于云端,移动终端的算力更为受限。想要把大模型装进手机,算力问题自然构成了第一重挑战。
计算单元之外,有限的内存单元,是大模型进手机面临的第二道难关:大模型推理需要大量计算资源做支撑,与此同时,内存大小决定了数据处理速度的上限以及推理的稳定性。
另外,在手机上跑大模型,也给电池带来了更大的压力。因此芯片能耗成为一大关键。
在各大厂商的最新探索之中,我们可以观察到,解决之道目前分为软、硬两路。
先来看硬件部分。
高通最新推出的第三代骁龙8移动平台,就被定位为高通“首个专门为生成式AI打造的移动平台”:
能够在终端侧运行100亿参数大模型,面向70亿参数大语言模型,每秒能生成20个token。
较之前代产品,第三代骁龙8最重要的变化,就是驱动终端侧AI推理加速的高通AI引擎。
这个AI引擎由多个硬件和软件组成,包括高通Hexagon NPU、Adreno GPU、Kryo CPU和传感器中枢。

其中最核心、与AI最密切相关的,是Hexagon NPU。
高通公布的数据显示,Hexagon NPU在性能表现上,比前代产品快98%,同时功耗降低了40%。

具体而言,Hexagon NPU升级了全新的微架构。更快的矢量加速器时钟速度、更强的推理技术和对更多更快的Transformer网络的支持等等,全面提升了Hexgon NPU对生成式AI的响应能力,使得手机上的大模型“秒答”用户提问成为可能。
Hexagon NPU之外,第三代骁龙8在Sensing Hub(传感器中枢)上也下了功夫:增加下一代微型NPU,AI性能提高3.5倍,内存增加30%。

值得关注的是,官方提到,Sensing Hub有助于大模型在手机端的“定制化”。随时保持感知的Sensing Hub与大模型协同合作,可以让用户的位置、活动等个性化数据更好地为生成式AI所用。
而在内存方面,第三代骁龙8支持LPDDR5X,频率从4.2GHz提高到了4.8GHz,带宽77GB/s,最大容量为24GB。
更快的数据传输速度,更大的带宽,也就意味着第三代骁龙8能够支持更大更复杂的AI模型。
并且,此番高通在内存和Hexagon NPU矢量单元之间增加了直连通道,进一步提高了AI处理效率。
恰逢骁龙峰会期间,SK海力士还特别宣布,其产品LPDDR5T已经在高通第三代骁龙8上完成了性能及兼容性验证,速度达到9.6Gbps。由此看来,搭载第三代骁龙8的手机在内存方面还有更多的选择。

除此之外,在CPU方面,第三代骁龙8采用“1+5+2”架构(1个主核心、5个性能核心和2个能效核心),相较于前代的“1+4+3”,将1个能效核心转换为性能核心。其中超大核频率提升到3.3GHz,性能核心频率提升到最高3.2GHz,能效核心频率提升到2.3GHz。
新架构下,Kryo CPU性能提高了30%,功耗降低了20%。
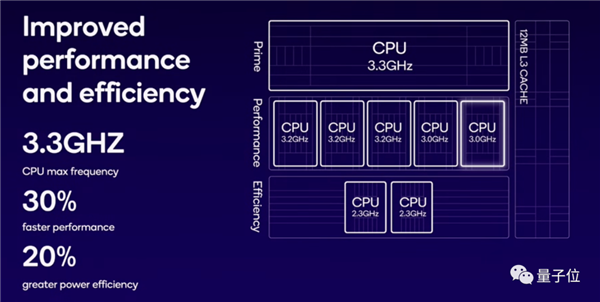
GPU方面,第三代骁龙8则在性能和能效方面均实现25%的提升。
值得一提的是,AI引擎之外,第三代骁龙8的ISP、调制解调器等其他模块,也已根植AI基因。
现在,高通的认知ISP是酱婶的:
支持多达12层的照片/视频帧实时语义分割;
融合生成式AI技术,支持声控拍照和视频编辑;
支持利用AI技术从视频中删除不需要的人和物;
支持AI扩展照片;……
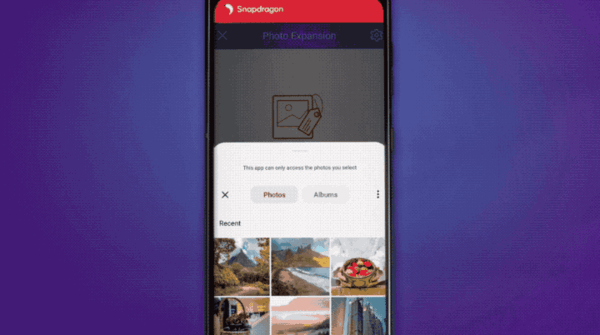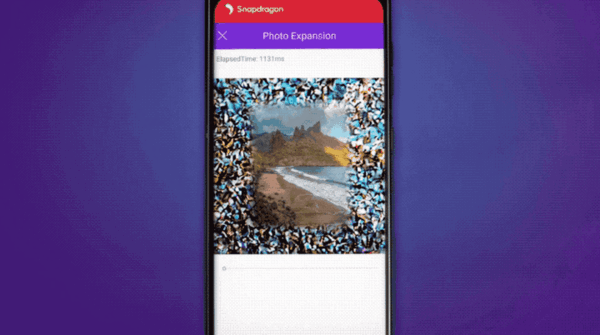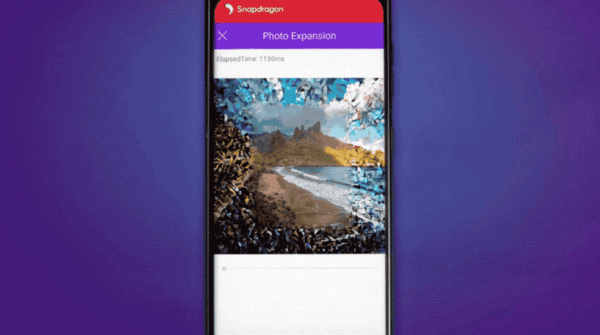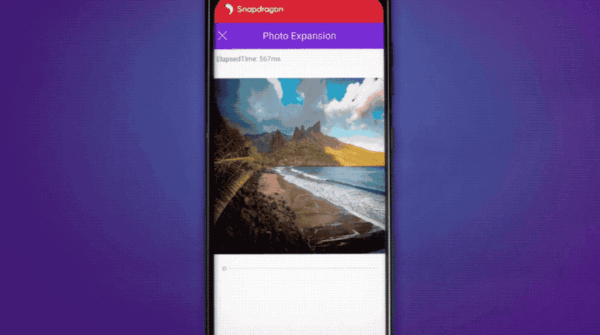
调制解调器同样有5G AI处理器的加持:通过分析信号完整性和信噪比,AI能够改善无线带宽、延迟等性能指标。
由此看来,在大模型进手机的过程中,行业领军者的硬件解决之道可以从两方面来总结:
其一,是针对算力、内存、能耗三要素的性能提升和功耗平衡。
其二,是用AI来定义硬件,跟AI技术本身做更深层的结合。
不过,虽说硬件技术能解决大模型移植到智能终端的关键难点,但要想让它真正落地应用,仍需要迈过另外一重门槛。
降低大模型软件开发门槛
这道门槛,具体可以分解为两个问题:
-技术更新、体积更大的模型,如何快速实时地装进手机?
-装进手机后,又要如何快速装进手机以外的智能终端?
要想解决这两大问题,就不能仅仅从硬件侧入手,而同样要在软件开发上做好准备。
首先,需要先增强智能终端对不同大模型的适配能力,即使是架构算法存在差异也同样能装进手机。
即使最新大模型体积超出预期,也要能确保在不影响性能的情况下,将之应用到智能终端。
这里依旧以高通为例。
从最早在手机上运行10亿参数Stable Diffusion,到快速基于骁龙8 Gen 3适配百亿参数大模型,背后实际上还离不开一类软件能力——
AI压缩技术。
最新的AI压缩技术,从高通今年发表在AI顶会上的几篇论文可以窥见一斑。
像是这篇被NeurIPS 2023收录的论文,就针对当前大模型的“基石”Transformer架构进行了量化相关的研究。

量化是压缩AI模型的一种经典方法,然而此前在压缩Transformer模型的时候,容易出现一些问题。
这篇论文提出了两种方法来对Transformer模型进行量化,在确保压缩效果的同时,进一步提升模型输出性能,确保模型看起来“更小更好”。
然后,还需要增强大模型软件在不同软件终端之间的通用性,进一步加速落地。
对于大模型而言,从一个硬件设备迁移到另一个硬件设备,并没有想象中那么容易。
不同的计算平台之间,硬件的配置往往差异很大,电脑上能运行的大模型,放到手机上还真不一定就能立刻运行。
而这也正是阻碍大模型在种类繁多、部件繁杂的智能终端落地的另一重原因。
对此,高通的准备是一个“转换器”一样的角色:高通AI软件栈。
这是一套容纳了大量AI技术的工具包,全面支持各种主流AI框架、不同操作系统和各类编程语言,能提升各种AI软件在智能终端上的兼容性。
不仅如此,这套软件栈还包含高通AI Studio,相当于将高通的所有AI工具集成到一起,直接进行可视化开发。
其中,如AI模型增效工具包、模型分析器和神经网络架构搜索(NAS)等都在里面。
AI软件只需要在里面从设计、优化、部署到分析“走一趟流程”,就能快速转换成在其他操作系统和平台上也可以运行的软件产品。
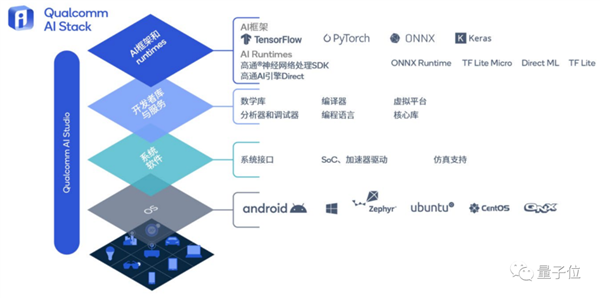
只需要一次开发,甚至是大模型软件的开发,就能让它在多个平台运行,不需要担心适配的问题,像Stable Diffusion就已经部署到其中,其他平台也同样可以随取随用了。
这样一来,不仅仅是将百亿参数大模型塞进手机,甚至还能将它塞进汽车、XR、PC和物联网。

原本的设备类型繁多的缺点也能化为优势,进一步加速大模型软件的落地。
总结来看,大模型移植到智能终端所需的技术,不仅是硬实力,软件上也同样需要有所储备。
所以,对于在大模型时代下蓄势待发的移动端软硬件厂商而言,究竟如何才能抓住这次难得的机遇?
或者说,各厂商要如何提前做好准备,才能确保大模型时代依旧屹立于技术浪潮之巅?
大模型时代需要怎样的终端芯片
一个时代有一个时代的计算架构。
深度学习时代是如此,计算摄影时代是如此,大模型时代依旧如此——
无论软硬件,「模力时代」下的智能终端芯片评判标准已经悄然生变。
一方面,对于硬件性能而言,芯片已经从单纯的硬件性能对比、算力较量、功耗计算,逐渐转变成对AI算力的比拼,甚至是对AI软硬件技术能力的全面要求。
这种转变,从大模型厂商巨头的技术储备栈变化可以窥见一斑。
以微软为例,这家科技巨头和云厂商,近期开始注重起AI软硬件结合的技术,如大模型训练等。
在微软前不久的一篇训练研究中,就系统阐述了大模型在FP8精度下训练的效果,能在同样硬件成本下,训练更大规模的大模型、同时确保训练出来的模型性能。
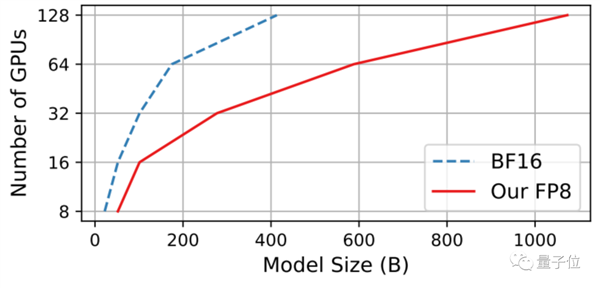
△图源论文FP8-LM: Training FP8 Large Language Models
以AI算法研究著称的OpenAI,则被曝出有造芯的意向,开始朝硬件方向的技术发力。
显然,从不同科技巨头最新研究中能看出,在这个技术日新月异的时代,手握一张底牌就能抓住机遇、打出自身价值的概率,正变得越来越低。
如果还停留在“硬件公司造好芯、软件公司做好算法”的阶段,势必只会被其他虎视眈眈的厂商超过,在「模力时代」失去已有的竞争力。
反观硬件场景有优势的芯片公司,亦是如此。
除了硬件性能的提升以外,与时俱进扩展软件技术栈、提升软硬件结合的AI能力,同样不可或缺。
高通在前阵子推出的白皮书中就提到,将大模型部署到个人智能终端上,不仅要考虑硬件,也同样需要考虑模型个性化、计算量等问题。
但相比等待大模型厂商去解决这些问题,高通选择自己在软件方面进行研究,最新成果也同样实时写成论文分享出来。

只有这样,才能更好地了解算法软件侧对于硬件的需求,从而更好地提升芯片的性能。
另一方面,对于算力更受限、用户范围更广的终端而言,未来的趋势必然是无缝互联。这就意味着,跨平台适用性会成为AI解决方案的关键。
这种动向,从今年的骁龙峰会上发布的Snapdragon Seamless技术就能窥见一斑。
像是将平板上的照片,用鼠标就能“一键平移”到PC,在电脑上进行快速处理:

处理完毕后,还能将照片在另一个设备上打开,并用PC的键盘给它重命名:

即使只有一个设备拥有键盘和鼠标,也能对各类设备进行无缝控制,甚至让AI软件也无障碍在各个设备之间连接使用。
对于数据传输延迟不是问题的未来而言,打通多终端协作和互联,势必是智能终端的下一个未来:
不仅手机和PC等不同的终端设备之间可以共享数据、更可能让同一套设备在不同的操作系统之间完成一系列流畅操作,像是手机和PC的音频在耳机之间无缝切换:

之前只有在手机上能使用的AI应用,有了这套系统就能扩展到千万台智能终端设备上,包括PC、XR、平板和汽车。
这样一来,大模型就不再会受限于某一台设备、或是某一个操作系统,而是能快速将已经在一类终端中实现的AI能力快速套用到更多设备中,最终实现“万物皆可大模型”的操作。
总结来看,在大模型时代下,AI厂商不仅需要具备软硬件结合的能力,更需要提前布局智能终端万物互联的未来,以「连接」技术加速大模型在场景下的落地应用。
高通已经给出了自己的行动路径。
对于其他不同企业而言,依旧要在场景中探索自身的价值,才可能在「模力时代」下找到新的出路。